
Part 2: Taking Your Skills to the Next Level
by Sarah Rodriguez
Welcome back! In the last article, we covered the fundamentals—DB2, z/OS Connect, and building your first REST APIs. If you worked through that material and actually built something, you’re already ahead of where I was at this stage.
Now it’s time to level up. We’re going to tackle the tools and patterns that separate “I can build an API” from “I can build a production-grade integration platform.”
Fair warning: This gets more complex. But I’ll keep it real and practical, just like before.
Week 13-14: Zowe – Your New Best Friend
Why Zowe Matters (A Quick Reality Check)
When I first heard about Zowe, I thought, “Great, another tool to learn.” But here’s the truth: Zowe changed how I work every single day.
Before Zowe, I was:
- Using 3270 emulators for everything
- Manually submitting JCL jobs and waiting
- FTPing files back and forth
- Copy-pasting between different tools
After Zowe, I have:
- Command-line access to mainframe resources
- Automated workflows for deployments
- Integration with modern CI/CD pipelines
- A way to make the mainframe feel like any other development environment
If you want to be a mainframe DevOps practitioner, Zowe is non-negotiable.
Day 92-94: Setting Up Your Zowe Environment
Step 1: Install Zowe CLI (5 minutes)
bash
# Install Zowe CLI globally
npm install -g @zowe/cli@zowe-v2-lts
# Verify it worked
zowe --versionIf you got an error, it’s probably Node.js version issues. Zowe needs Node 14+. Check it: node --version
Step 2: Create Profiles (Connection Configs)
This is where you tell Zowe how to connect to your mainframe environments.
bash
# Development environment
zowe profiles create zosmf-profile dev_system \
--host dev.mainframe.com \
--port 443 \
--user youruserid \
--password \
--reject-unauthorized false
# Test environment
zowe profiles create zosmf-profile test_system \
--host test.mainframe.com \
--port 443 \
--user youruserid \
--password \
--reject-unauthorized falsePro tip: Use --reject-unauthorized false in dev/test only. In production, get real SSL certificates.
Step 3: Test Your Connection
bash
# Check if z/OSMF is responding
zowe zosmf check status --zosmf-profile dev_system
# List your datasets
zowe files list dataset "YOURID.*" --zosmf-profile dev_system
# View a dataset
zowe files view data-set "YOURID.JCL(MYJOB)" --zosmf-profile dev_systemIf this works, you just controlled a mainframe from your terminal. Pretty cool, right?
Day 95-98: Zowe in Your Daily Workflow
Here’s how I actually use Zowe every day:
Scenario 1: Deploy a COBOL program
bash
# Upload updated source code
zowe files upload file-to-data-set \
./local/CUSTINQ.cbl \
"YOURID.SOURCE.COBOL(CUSTINQ)" \
--zosmf-profile dev_system
# Submit compile JCL
zowe jobs submit data-set \
"YOURID.JCL(COMPILE)" \
--zosmf-profile dev_system \
--view-all-spool-content
# Check the output right there in your terminalBefore Zowe: 5-10 minutes of clicking through screens.
With Zowe: 30 seconds, and it’s scriptable.
Scenario 2: Automate Your Deployments
Create a bash script: deploy.sh
bash
#!/bin/bash
PROFILE="dev_system"
USERID="YOURID"
echo "Starting deployment..."
# Upload all COBOL programs
for file in ./cobol/*.cbl; do
filename=$(basename "$file" .cbl)
echo "Uploading $filename..."
zowe files upload ftds \
"$file" \
"$USERID.SOURCE.COBOL($filename)" \
--zosmf-profile $PROFILE
done
# Compile them
echo "Compiling programs..."
zowe jobs submit ds "$USERID.JCL(COMPALL)" \
--zosmf-profile $PROFILE
# Update z/OS Connect services
echo "Updating z/OS Connect services..."
# Your service update commands here
echo "Deployment complete!"Now deployment is: ./deploy.sh
This is where the DevOps magic happens.
Day 99-102: API Mediation Layer – Enterprise Grade Stuff
Okay, this is where we go from “I have some APIs” to “I have an API platform.”
What is API Mediation Layer?
Think of it as an API Gateway specifically designed for mainframe services. It gives you:
- Single entry point for all mainframe APIs
- Authentication/authorization in one place
- Service discovery (no more hardcoded URLs)
- Load balancing and high availability
- Unified documentation (API catalog)
Real-world scenario that changed my mind:
At my company, we had 12 different z/OS Connect servers across departments. Developers had to:
- Know which server had which service
- Manage 12 different sets of credentials
- Handle 12 different URLs
After implementing API Mediation Layer:
- One URL:
https://api.company.com - One login: SSO with enterprise credentials
- Service catalog: Browse all available APIs in one place
Developers could actually find and use our mainframe services.
Registering Your Services with API ML
Remember that customer inquiry service we built with z/OS Connect? Let’s register it.
Create service-definition.yml:
yaml
services:
- serviceId: customer-api
title: Customer Management API
description: REST API for customer operations
catalogUiTileId: customer
instanceBaseUrls:
- https://zosconnect.company.com:8443
homePageRelativeUrl: /zosConnect/services
routes:
- gatewayUrl: api/v1
serviceRelativeUrl: zosConnect/services/customerInquiry
authentication:
scheme: zoweJwt
apiInfo:
- apiId: customer.v1
gatewayUrl: api/v1
swaggerUrl: https://zosconnect.company.com:8443/zosConnect/services/customerInquiry/api-docsDeploy it:
bash
# Copy definition to API ML config directory
cp service-definition.yml /global/zowe/instance/workspace/api-mediation/
# Restart API ML discovery service
zowe zos-jobs submit local-file restart-discovery.jclNow your API is discoverable:
- Developers can find it in the catalog
- It’s automatically load-balanced
- Authentication is handled by the gateway
Week 15-16: Production Patterns That Actually Work
Day 103-105: Service Orchestration (The Real World is Messy)
Here’s the thing nobody tells you about mainframe APIs: You rarely call just one service.
Real business processes need:
- Data from multiple DB2 tables
- CICS transactions
- IMS database queries
- Maybe a batch job submission
- All of this coordinated, with error handling
Let me show you how I handle this.
Scenario: Customer Onboarding
Business requirement: “When we onboard a customer, we need to create their profile, set up their accounts, configure services, and send welcome notifications.”
That’s at least 4 different mainframe calls. Here’s my orchestration pattern:
javascript
class CustomerOnboardingOrchestrator {
async onboardCustomer(request) {
const transactionId = this.generateTransactionId();
const context = {
transactionId,
startTime: new Date(),
rollbackStack: []
};
try {
// Step 1: Create customer (DB2 via z/OS Connect)
const customer = await this.createCustomer(
request.customer,
context
);
// Step 2: Create accounts in parallel (CICS transactions)
const accounts = await Promise.all(
request.accounts.map(acct =>
this.createAccount(customer.customerId, acct, context)
)
);
// Step 3: Configure services (IMS)
const services = await this.setupServices(
customer.customerId,
request.services,
context
);
// Step 4: Send notifications (external system)
await this.sendNotifications(customer, context);
// Log success
await this.auditSuccess(context);
return {
success: true,
transactionId,
customer,
accounts,
services
};
} catch (error) {
// Rollback everything we did
await this.rollback(context, error);
throw error;
}
}
async createCustomer(customerData, context) {
try {
const result = await this.callZosConnect(
'/zosConnect/services/customerCreate',
customerData
);
// Save rollback info
context.rollbackStack.push({
action: 'deleteCustomer',
customerId: result.customerId
});
return result;
} catch (error) {
throw new Error(`Customer creation failed: ${error.message}`);
}
}
async rollback(context, originalError) {
console.log(`Rolling back transaction ${context.transactionId}`);
// Execute rollback actions in reverse order
for (let i = context.rollbackStack.length - 1; i >= 0; i--) {
const rollbackAction = context.rollbackStack[i];
try {
switch (rollbackAction.action) {
case 'deleteCustomer':
await this.deleteCustomer(rollbackAction.customerId);
break;
case 'deleteAccount':
await this.deleteAccount(rollbackAction.accountId);
break;
}
} catch (rollbackError) {
// Log but don't throw - continue rolling back
console.error(`Rollback failed:`, rollbackError);
}
}
await this.auditFailure(context, originalError);
}
}Key patterns here:
- Transaction ID tracking – Every request gets a unique ID for tracing
- Rollback stack – As we create things, we remember how to undo them
- Parallel execution where possible – Accounts created simultaneously
- Comprehensive error handling – If anything fails, we rollback everything
This saved my bacon multiple times. In production, you WILL have partial failures. This pattern ensures you don’t leave orphaned data.
Day 106-109: Monitoring (If You Can’t Measure It, You Can’t Fix It)
Here’s my monitoring philosophy: Log everything, alert on anomalies, visualize trends.
Performance Tracking Middleware:
javascript
class APIMonitor {
createMiddleware() {
return (req, res, next) => {
const startTime = Date.now();
const requestId = uuidv4();
// Track request
req.monitoring = { requestId, startTime };
// Intercept response
const originalSend = res.send;
res.send = function(data) {
const endTime = Date.now();
const duration = endTime - startTime;
// Log metrics
metricsCollector.record({
requestId,
endpoint: req.path,
method: req.method,
statusCode: res.statusCode,
duration,
timestamp: new Date()
});
// Check SLA violations
if (duration > 2000) { // 2 second threshold
alertManager.sendAlert({
type: 'SLOW_RESPONSE',
endpoint: req.path,
duration,
requestId
});
}
originalSend.call(this, data);
};
next();
};
}
}What I monitor:
- Response time – P50, P95, P99 percentiles
- Error rate – % of 4xx and 5xx responses
- Throughput – Requests per minute
- Mainframe resource usage – DB2 connections, CICS threads
- Business metrics – Successful vs failed transactions
My Dashboard Queries:
sql
-- Find slowest endpoints (last 24 hours)
SELECT
endpoint,
COUNT(*) as request_count,
AVG(duration_ms) as avg_duration,
MAX(duration_ms) as max_duration,
PERCENTILE_CONT(0.95) WITHIN GROUP (ORDER BY duration_ms) as p95_duration
FROM api_metrics
WHERE timestamp > NOW() - INTERVAL '24 hours'
GROUP BY endpoint
ORDER BY avg_duration DESC;
-- Error rate by endpoint
SELECT
endpoint,
COUNT(*) as total_requests,
SUM(CASE WHEN status_code >= 500 THEN 1 ELSE 0 END) as errors,
(SUM(CASE WHEN status_code >= 500 THEN 1 ELSE 0 END) * 100.0 / COUNT(*)) as error_rate_pct
FROM api_metrics
WHERE timestamp > NOW() - INTERVAL '1 hour'
GROUP BY endpoint
HAVING error_rate_pct > 1.0; -- Alert if error rate > 1%Alerting rules I actually use:
- Response time > 2 seconds → Warning
- Response time > 5 seconds → Critical
- Error rate > 1% → Warning
- Error rate > 5% → Critical
- Any 500 error → Immediate notification
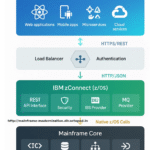
Putting It All Together: A Real Production Setup
Let me show you what a complete, production-ready architecture looks like based on what I’ve built:
┌─────────────────────────────────────────────┐
│ API Mediation Layer (Zowe) │
│ - Service Discovery │
│ - Load Balancing │
│ - Authentication (JWT) │
└──────────────┬──────────────────────────────┘
│
┌──────────┴──────────┬──────────────┐
│ │ │
┌───▼────┐ ┌──────▼───┐ ┌────▼────┐
│ z/OS │ │ z/OS │ │ Node.js │
│Connect │ │ Connect │ │Orchestr.│
│Server 1│ │ Server 2 │ │ Layer │
└───┬────┘ └─────┬────┘ └────┬────┘
│ │ │
└──────┬─────────────┴──────────────┘
│
┌──────▼─────────────────────┐
│ Mainframe Resources │
│ - DB2 Databases │
│ - CICS Transactions │
│ - IMS Programs │
│ - Batch Jobs │
└────────────────────────────┘Key components:
- API Mediation Layer – Single entry point, handles auth
- Multiple z/OS Connect instances – High availability
- Orchestration layer – Complex workflows, compensation logic
- Monitoring everywhere – Metrics, logs, traces
Final Thoughts: What I Wish I’d Known Earlier
After 15 years in this space, here’s my hard-earned wisdom:
1. Start Simple, Scale Smart
Don’t try to build Netflix on day one. Get one API working well, then build the next one. I’ve seen too many “comprehensive modernization initiatives” fail because they tried to do everything at once.
2. Security From Day One
I learned this the hard way. Adding security later is 10x harder than building it in from the start. Use SSL, require authentication, log everything.
3. Documentation is Love
Future you (or your replacement) will either thank you or curse you based on your documentation. I keep:
- API specifications (OpenAPI)
- Deployment runbooks
- Troubleshooting guides
- Architecture diagrams
4. Test Everything
Mainframes are stable, but your integration layer isn’t—yet. Automated tests saved me from so many production incidents. Test:
- Individual services (unit tests)
- End-to-end workflows (integration tests)
- Performance under load (stress tests)
- Failure scenarios (chaos tests)
5. Monitor Like Your Job Depends On It
Because it does. The first time production goes down at 2am, you’ll wish you had better monitoring. I monitor:
- Is it working? (availability)
- Is it fast? (performance)
- Is it secure? (audit logs)
- Is it being used? (adoption metrics)
You’re Ready
If you’ve worked through both articles, you now know more about mainframe integration than 90% of developers out there. Seriously.
You can:
- Design API-ready databases in DB2
- Build REST services from COBOL programs
- Use Zowe for modern DevOps workflows
- Implement enterprise-grade API management
- Build production-ready orchestration patterns
- Monitor and optimize your integrations
What’s next is up to you.
Maybe you’ll modernize your company’s customer management system. Maybe you’ll build a proof of concept that gets budget approval. Maybe you’ll just become the person everyone asks when they need to integrate with the mainframe.
Whatever you do, remember: The mainframe isn’t going anywhere. The companies running mainframes are looking for people who can bridge the old and the new. That’s you now.
Keep building. Keep learning. And when you solve a tricky problem, write it down—someone else will need that answer someday.
Stay curious,
Sarah Rodriguez
Mainframe operator turned DevOps advocate | 15 years keeping the lights on and making them brighter
P.S. – If you hit a wall with any of this, that’s normal. Reach out to the mainframe community. We’re small enough that people actually help each other. Find your local mainframe user group, join the Zowe Slack, or just search for “mainframe DevOps” on LinkedIn. You’re not alone in this journey.